登录
- 微信登录
- 手机号登录
微信扫码关注“汇帮科技”快速登录
Loading...
点击刷新
请在微信【汇帮科技】内点击授权
300秒后二维码将过期
二维码已过期,点击刷新获取新二维码
登录
登录
其他登录方式
修改日期:2024-11-06 13:10
你知道吗?我们每天都要处理大量的PDF文件,而这些文件的名称往往是杂乱无章的。在这种情况下,你会怎么做?当然,不会像我一样,一边打呵欠一边思考“如何快速提取PDF文件名”这个问题!
其实,解决这个问题很简单。有这么一个魔法工具,它能帮助你轻松批量提取PDF文件名,让你的工作变得更加高效和井然有序。这款工具叫做汇帮文件名提取器。打开软件,就能看到一个简洁易用的界面。随后,你只需要将要处理的PDF文件拖动到软件中,就会发现所有文件的名称都会被自动提取出来。
这个工具不仅能帮助你快速批量提取PDF文件名,还能减少因为手工操作而产生的错误率。它真的能够成为你的工作小助手。

方法一:借助“汇帮文件名提取器”,快速高效地提取PDF文件名称
使用汇帮文件名提取器的全新体验
步骤1:在未触摸过此款神奇软件的人眼中,首先需要进行的是“如何下载并安装它”的教程。在这个世界上,没有比快速找到答案更快的方法了,所以我们打开了百度的首页,输入关键词汇帮文件名提取器,进入官网下载。通过一步一步的指引,我们成功地下载了它并将其安装到了我们的电脑中。
软件名称:汇帮文件名提取器
下载地址:https://www.huibang168.com/download/wGi5oWZ2FL8S
步骤2:现在,软件已经准备好使用了,而我们则需要打开它来体验一下其中的强大功能。为了完成我们的任务,那么选择“文件名提取”就成了最佳选择,因为我们的目的是批量提取某个目录下的PDF文件的名字。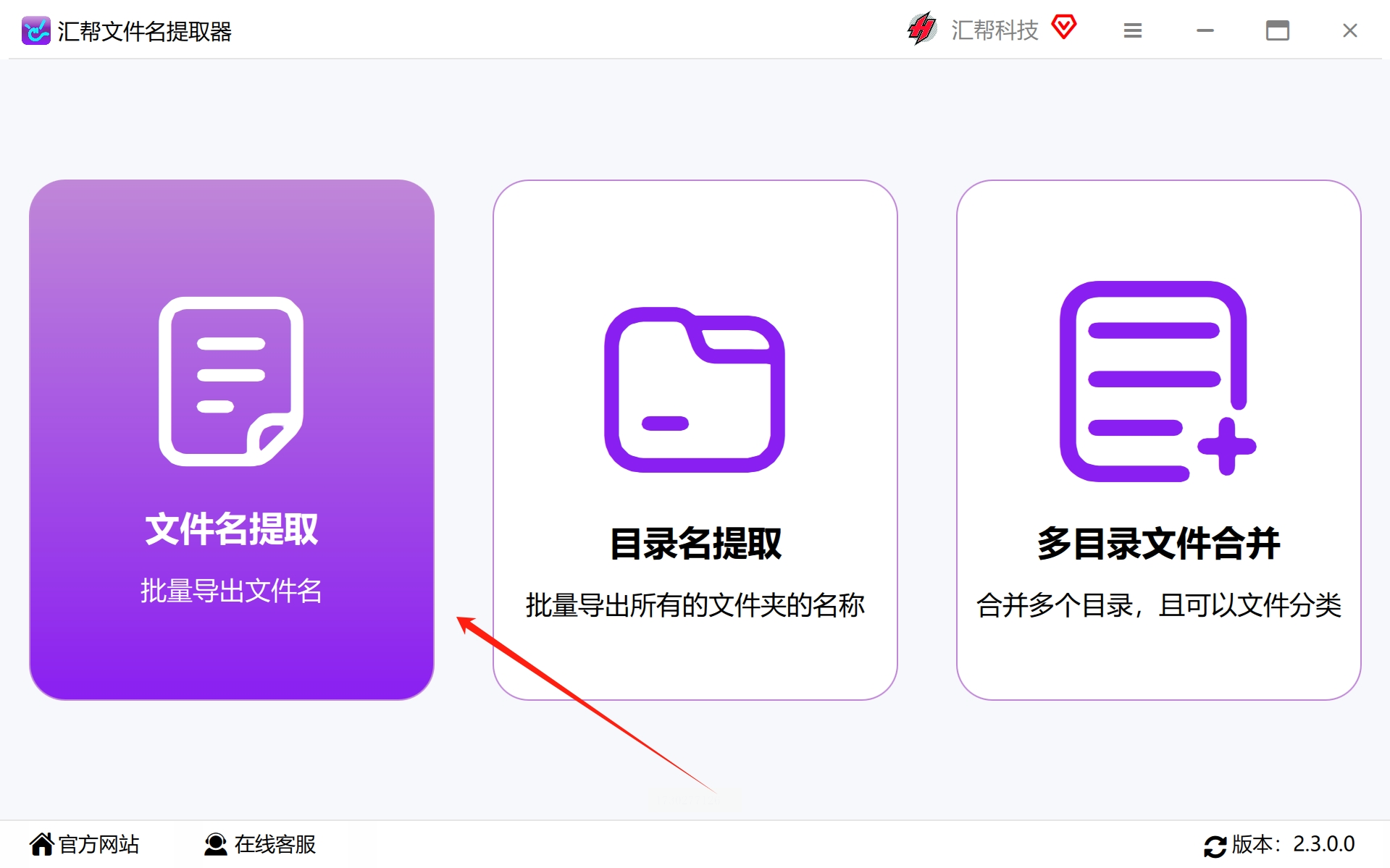
步骤3:在这一步里,需要我们手动添加所需提取的PDF文件或者整个目录,这样可以实现批量操作,没有数量限制。
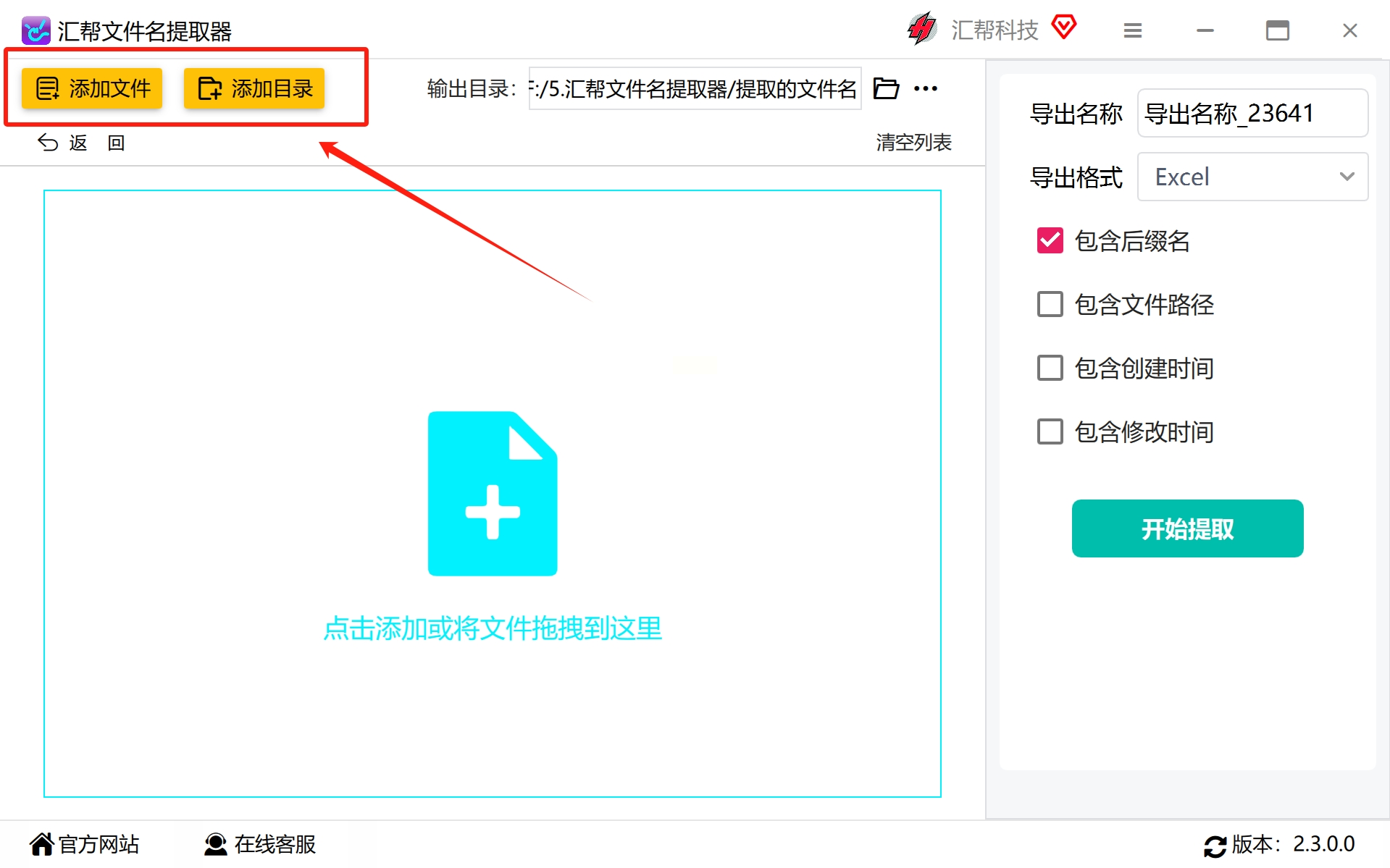
通过一步一步的指引,我们成功地添加了所有需要提取的PDF文件,并准备好进行下一步操作了。
步骤4:在这一步里,我们需要设置好导出的文件名,如果不进行设定,那么系统会自动生成一个名字。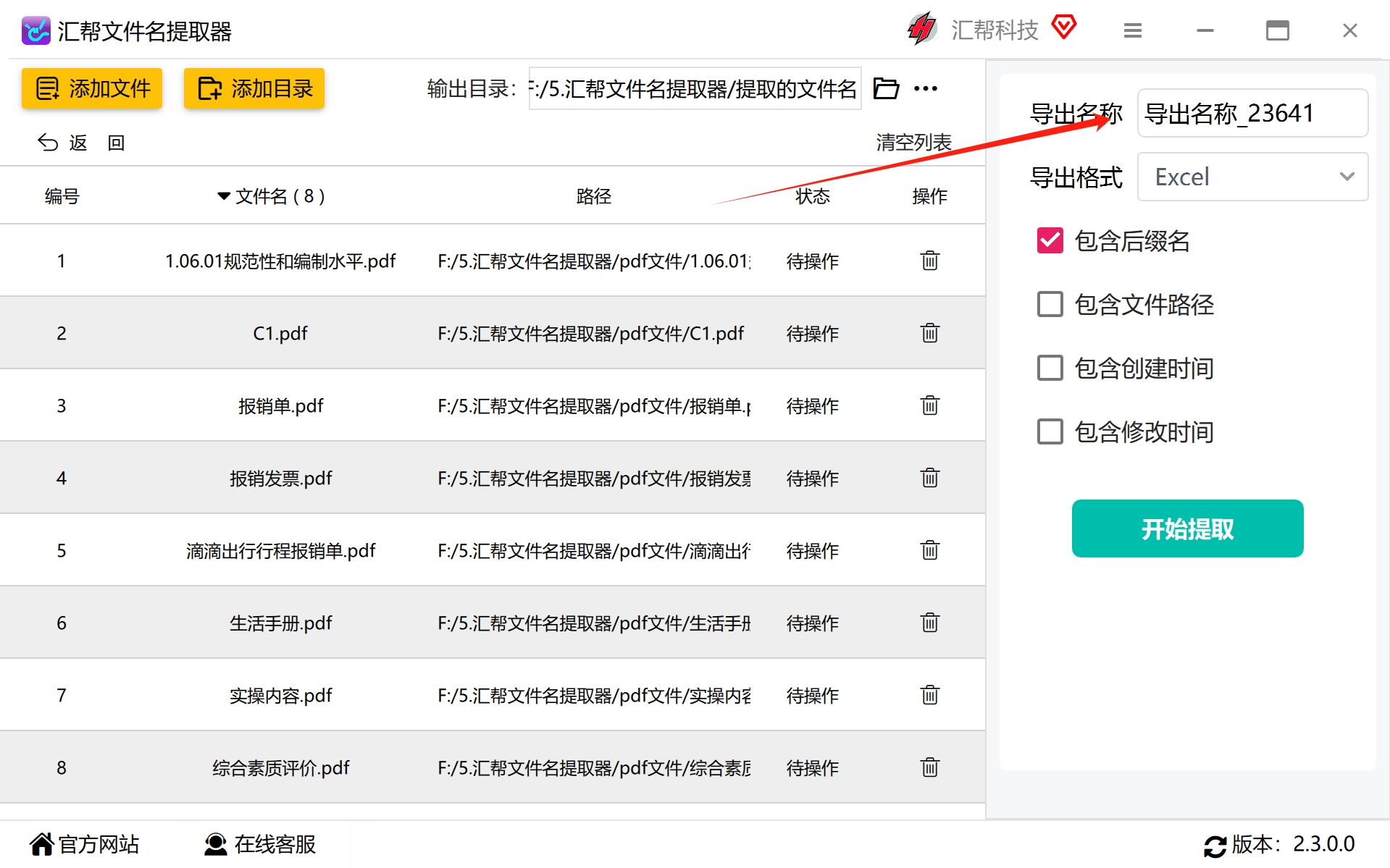
我们可以根据自己的喜爱自由选择想要的输出文件名和格式。
步骤5:进入到了最精彩的部分,在这一步里,我们需要选择你想导出的文件类型,有txt,csv,excel等多种类型供你选择。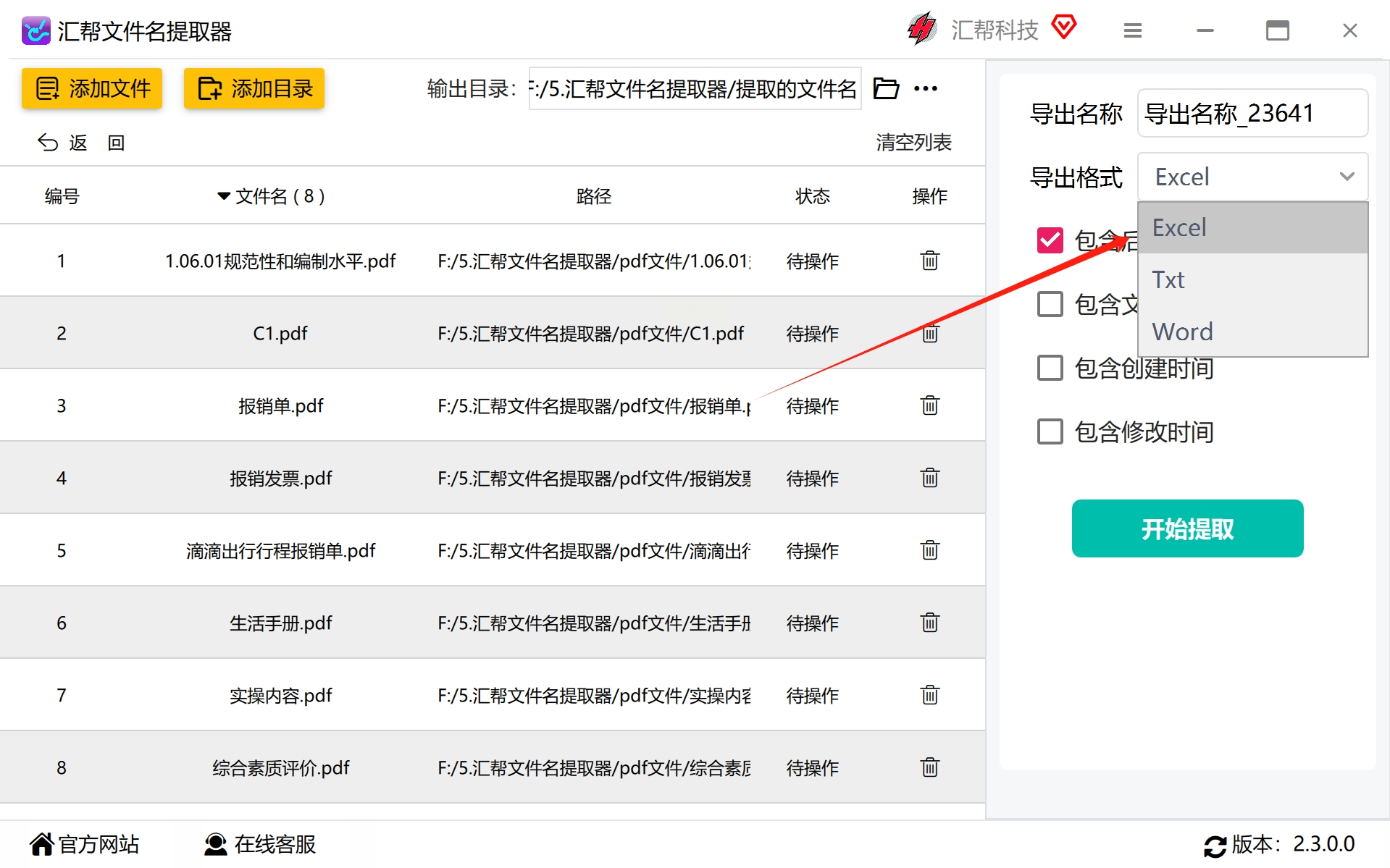
在这个界面中,我们选择了我们喜欢的excle格式,然后继续下一步操作。
步骤6:最后一点,这是一个很重要的设置,但是不要担心,因为这也是一步一步指引出来的。
在这一步里,我们可以根据需求进行相应选项的勾选,例如后缀名,文件路径,创建时间,修改时间等,然后点击开始提取就好。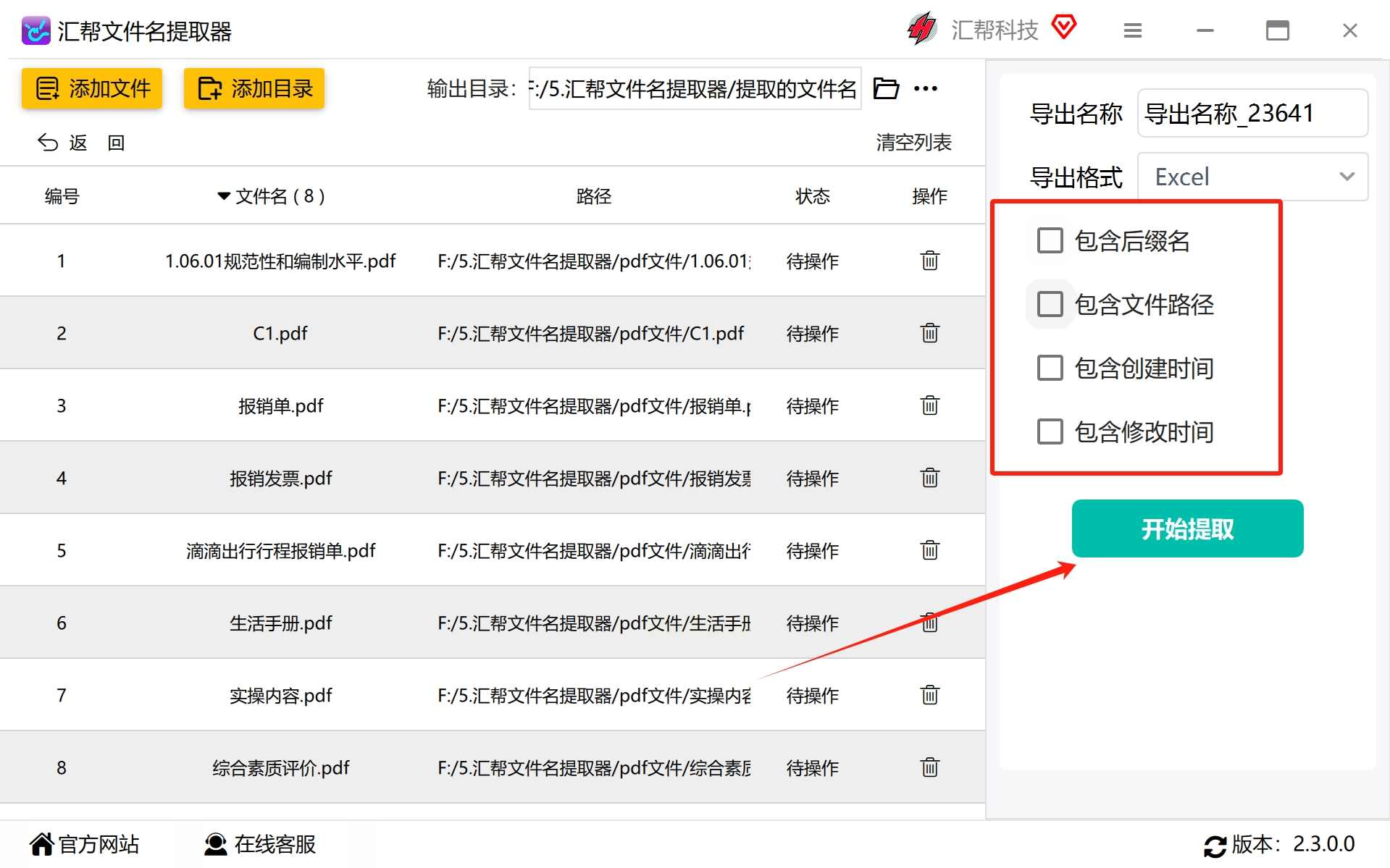
这里我们分别对以上选项进行了设置和选择,然后继续下一步操作。
步骤7:最后一步就是最重要的启动提取过程,这样一来,我们只需要耐心等待系统完成提取任务然后提示你已经完成。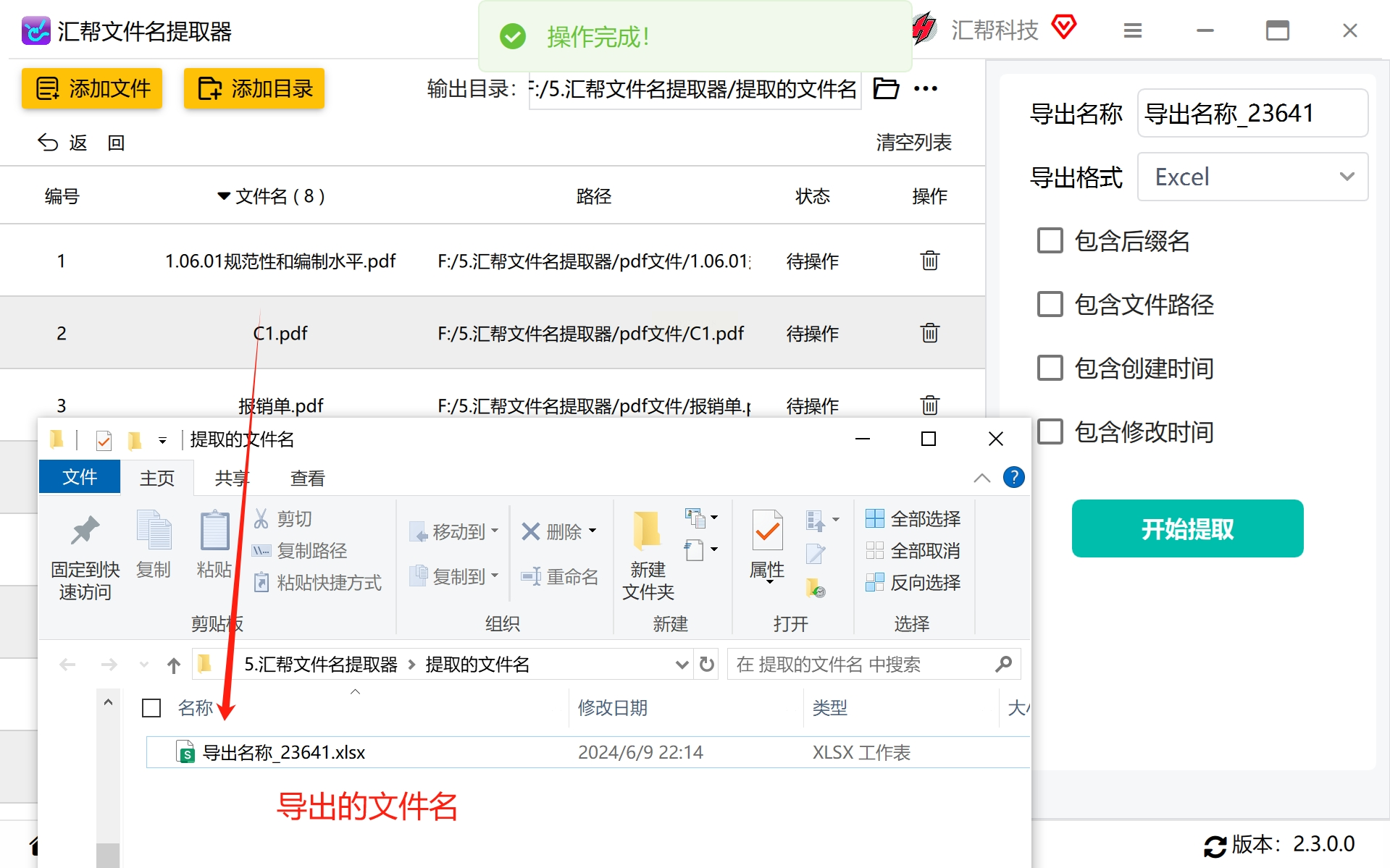
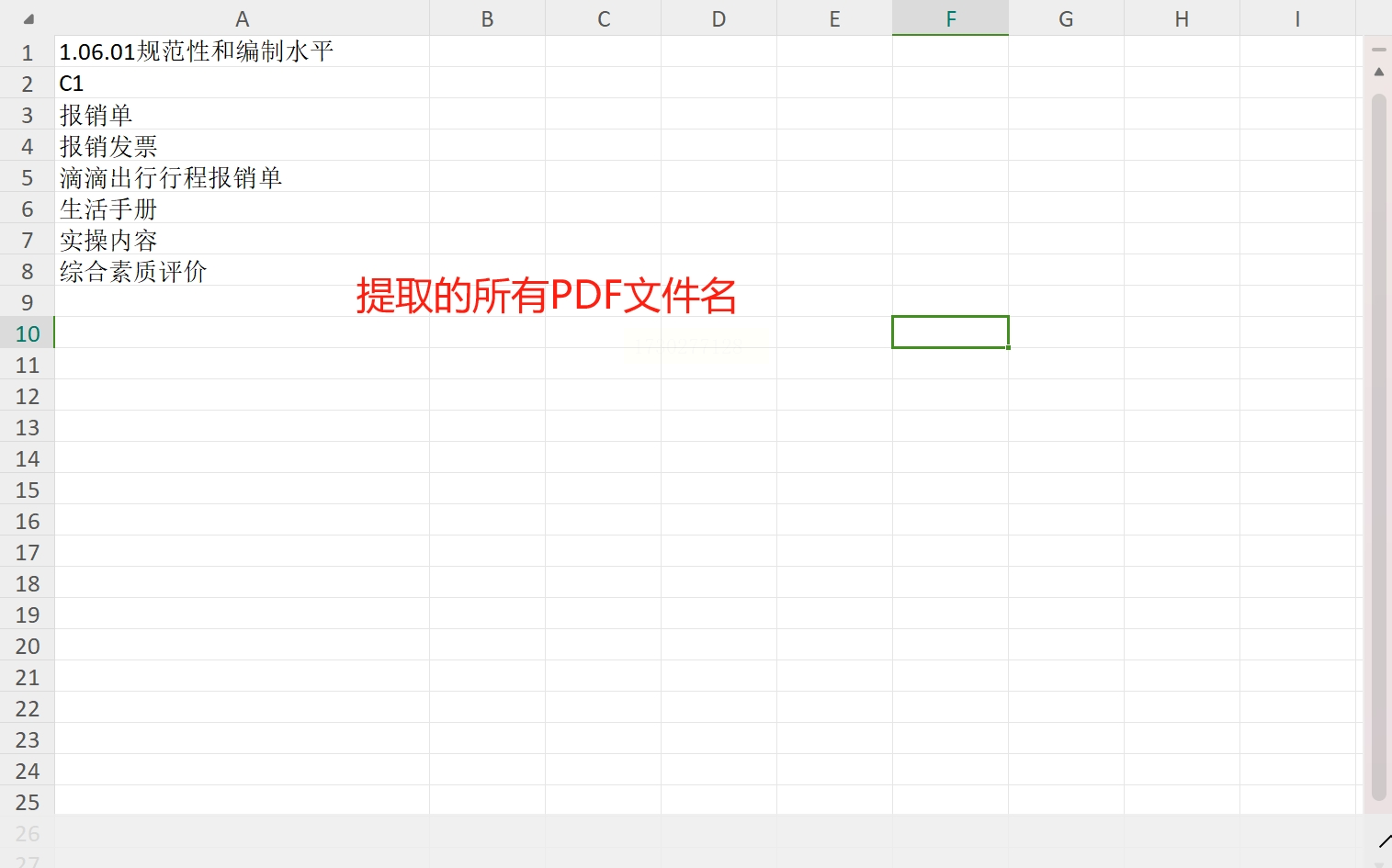
等待结束后,系统会自动跳转到你的指定输出路径中,你只需简单的打开预设好的文件即可查看得到的结果。
方法二:批量提取cmd命令使用
批量提取 CMD 命令提示符
批量复制PDF文件名到Excel:操作指南
在日常工作中,处理大量PDF文件的名称是一项重复性任务。想想如果你可以使用命令行来自动化这个过程,那会有多么方便!以下是步骤:
第一步:打开命令提示符
按下 Win + R 键,输入 cmd,然后按 Enter键。这将弹出命令提示符窗口。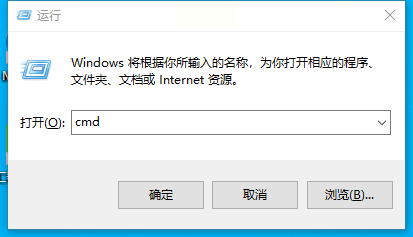
第二步:导航到PDF文件夹
在命令提示符中,使用 cd 命令切换到包含PDF文件的文件夹。例如:
```cmd
cd C:\Users\YourUsername\Desktop\PdfFolder
```
这将载入你要操作的PDF文件夹。
第三步:生成PDF文件名列表
运行以下命令,将PDF文件名导出到一个文本文件中:
```cmd
dir /b *.pdf > filenames.txt
```
这个命令会在当前目录下生成一个名为 filenames.txt 的文本文件,包含所有PDF文件的名称。
第四步:将文本文件导入Excel
打开Excel,并新建一个工作簿。转到“数据”选项卡,选择“从文本/CSV”,然后浏览并选择刚刚生成的 filenames.txt 文件点击“导入”。
在导入向导中,确保分隔符设置为“无”或“制表符”,然后点击“加载”或“导入”。这样,你就可以将PDF文件名批量导入到Excel工作表中了。
Tips 和 Tricks
* 如果你有很多PDF文件需要处理,可以使用 Windows 的批处理功能来自动化这个过程。
* 你也可以使用第三方工具,如 AutoHotkey 或 PowerShell 脚本来实现这一点。
* 请确保你的 Excel 工作簿和 PDF 文件位于同一个盘符下,以便 Excel 能够正确地读取文件。
常见问题解答
Q: 我的PDF文件名有特殊字符,会不会导致Excel导入错误?
A: 是的,如果你的PDF文件名包含特殊字符,可能会导致Excel导入错误。建议你尝试使用不同的分隔符或编码方式来解决此问题。
总结
通过以上步骤,你已经成功地将PDF文件名批量复制到Excel中了!这将大大提高你的工作效率,减少繁琐的重复性任务。
方法三:使用“小船文件名处理器”批量提取文件名称
在软件界面上,一切都是如此简单:
步骤1:启动小船并开启神奇模式
打开电脑桌面的"小船批量处理器"图标,这个神秘的工具将帮助我们完成惊人任务。
点一下左侧功能栏上的"提取文件名称"按钮,准备好迎接即将到来的魔术。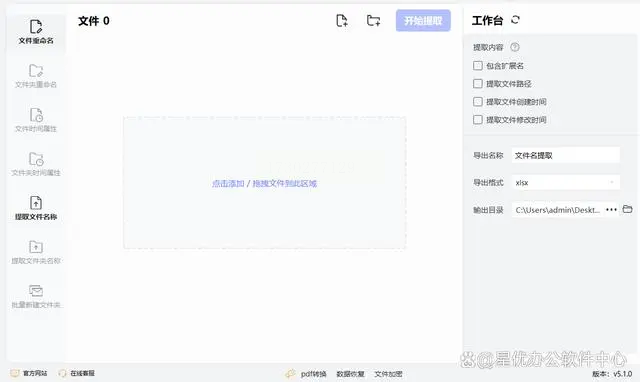
步骤2:添加PDF宝藏
点击软件界面上的"添加文件"按钮,或是手动拖拽方式,将所有需要提取的PDF文件都加入工具箱中。
确保所有文件都安全抵达目的地,准备好被神奇操作。
步骤3:设置提取条件
打开右侧的"提取内容"设置区域,勾选你想要提取的内容类型。这一步很重要,因为我们要准确捕捉PDF文件中的宝贵信息。
通常情况下,我们只需要简单的默认设置就足够了。
步骤4:设置导出清单
在软件指定位置输入你希望导出的Excel文件名称,既美观又实用。这一步骗很重要,因为我们要给提取结果命名并保存。
选择"xlsx"作为导出格式,这是标准的Excel表格格式。
步骤5:启动神奇模式
一旦所有设置完成,就可以点击软件界面上的"开始提取"按钮了。这时候,工具就会自动工作,它将批量提取PDF文件中的文件名,并把结果保存在之前设置好的Excel文件中。
等待提取任务完成的过程中,不要着急,你一定会收到提示信息。
步骤6:查看提取结果
任务完成后,软件通常会给你发送提取成功的通知,并提供前往导出文件夹的快捷方式。
点击"前往导出文件夹",就可以直接打开保存提取结果的Excel文件所在的位置。
最后!
打开Excel文件,你会发现所有PDF文件名都已整齐地排列在表格中。这就是我们的终极目标——一键式PDF文件名提取成功!
方法四:Windows PowerShell命令使用手册
PDF文件名提取之旅
在 Windows 系统中,PowerShell 是一个强大的命令行工具,可以帮助你批量提取 PDF 文件名。以下是一步一步的指南,将带你穿越 PowerShell 世界,轻松地提取你想要的 PDF 文件名。
第一步:准备好你的文件夹
首先,你需要指定包含 PDF 文件的文件夹路径。在 PowerShell 中,可以使用 `$pdfDirectory` 变量来存储这个路径。例如:
```powershell
$pdfDirectory = "C:\path\to\your\pdf\folder"
```
第二步:获取 PDF 文件名
接下来,使用 `Get-ChildItem` 命令获取 PDF 文件,并使用 `Select-Object` 获取文件名。你可以将以下代码添加到你的 PowerShell 脚本中:
```powershell
$pdfFilenames = Get-ChildItem -Path $pdfDirectory -Filter "*.pdf" -File | Select-Object -ExpandProperty Name
```
这个命令会遍历 `$pdfDirectory` 文件夹,筛选出所有 PDF 文件,并获取它们的文件名。
第三步:输出 PDF 文件名
现在,你可以使用 `Write-Output` 命令输出 PDF 文件名。如果你想要将输出保存到一个文本文件中,可以使用 `Out-File`命令:
```powershell
foreach ($filename in $pdfFilenames) {
Write-Output $filename
}
或
Get-ChildItem -Path $pdfDirectory -Filter "*.pdf" -File | Select-Object -ExpandProperty Name | Out-File "pdf_filenames.txt"
```
注意事项
请记得替换 `C:\path\to\your\pdf\folder` 为实际的 PDF 文件存放文件夹路径。运行 PowerShell 脚本后,它会输出该文件夹中所有 PDF 文件的文件名。如果你需要将输出保存到一个文本文件中,请确保指定完整的文件路径。
方法五:批量图片下载器
本文将向你展示如何使用Python脚本来实现这项功能。
步骤一:准备工作
首先,我们需要安装一个叫做`os`的Python模块,它负责操作系统相关的事务。我们可以通过以下命令来完成:
```bash
pip install os
```
接下来,我们要准备一个 Python 脚本,用于批量提取PDF文件名。这也就是我们的主要任务。
步骤二:编写脚本
现在,让我们开始编写这个脚本吧!下面是我们的代码:

在这个脚本中,我们定义了一个函数`批量提取PDF文件名(file_path)}`,其作用是将指定的文件夹及其子文件夹中的所有PDF文件名称收集起来。我们还需要传入文件夹路径作为参数。
步骤三:执行脚本
当你拥有了这个脚本后,请确保在命令行中使用Python解释器来运行它,如下所示:
```bash
python 批量提取PDF.py
```
其中,`批量提取PDF.py` 是你的脚本文件名。
步骤四:欣赏结果
当你执行了这个脚本后,它将会输出指定文件夹及其子文件夹中所有PDF文件的名称。这些名称将按照它们出现在文件系统中的顺序打印出来。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
在数字时代,处理大量的PDF文件已成为常见挑战,尤其是在报告、合同和研究资料等领域。传统的逐一记录每个文件名称手法,不仅耗时费力,还容易出错。
然而,与之对应的是一种高效工具:“汇帮文件名提取器”。这种器具能够快速、高效地从大批量PDF文件中提取所需文件名,让用户在短时间内获得文件名列表,从而极大地节省了时间成本和精力。
使用批量PDF文件名提取器,无论是个人还是专业人士,都能提高工作效率和准确性。这种器具不仅适用于管理文档库,还有助于减少错误的发生,使整个流程更加顺畅。
借助批量PDF文件名提取器,文档管理将变为一项轻松的任务,让用户能够专注于更重要的事务。这类工具已成为许多专业人士和机构的必备品之一,帮助他们高效地处理大量PDF文件。
如果想要深入了解我们的产品,请到 汇帮科技官网 中了解更多产品信息!
没有找到您需要的答案?
不着急,我们有专业的在线客服为您解答!

请扫描客服二维码

