登录
- 微信登录
- 手机号登录
微信扫码关注“汇帮科技”快速登录
Loading...
点击刷新
请在微信【汇帮科技】内点击授权
300秒后二维码将过期
二维码已过期,点击刷新获取新二维码
登录
登录
其他登录方式
修改日期:2024-11-07 13:00
在数字化时代,我们的日常工作中不可或缺的一部分就是PDF文件了。然而随着PDF文件数量的不断增加,如何高效地管理这些文件成为了一个头疼的问题。那么如何快速批量提取PDF文件名?其实有几个简单又实用的方法可以帮助你轻松解决这一难题。
首先,我们生活中会遇到很多需要处理大量PDF文件的情况,比如整理或管理这些文件。但是手动一个个复制粘贴显然效率低下,且容易出错。幸运的是,有些简单的工具可以帮助我们快速完成这项任务。例如,你可以使用市面上的一些专门的文件名提取工具。
这里需要注意的是,这类工具一般都具有简洁易用的界面和强大的功能,能够满足不同用户的需求。比如说,你可以尝试使用汇帮文件名提取器,它就是一个很棒的选择。这款软件不仅能快速批量提取PDF文件名,还能帮助你轻松管理你的文档。使用它你就可以轻松地解决之前提到的那个问题了。

第1种方法:高效提取PDF文件名称软件-"汇帮文件名提取器"
借助“汇帮文件名提取器”这款软件能够帮助我们以极高效率从多个PDF文档中提取所需的文件名
步骤1:对于初次接触此款软件的使用者而言,首先需进行相关搜索,找到“汇帮文件名提取器”并将其下载至个人计算机中进行安装
步骤2,启动已成功安装的软件,鉴于我们需要批量提取PDF文件名,因此在此处选择“文件名提取”功能选项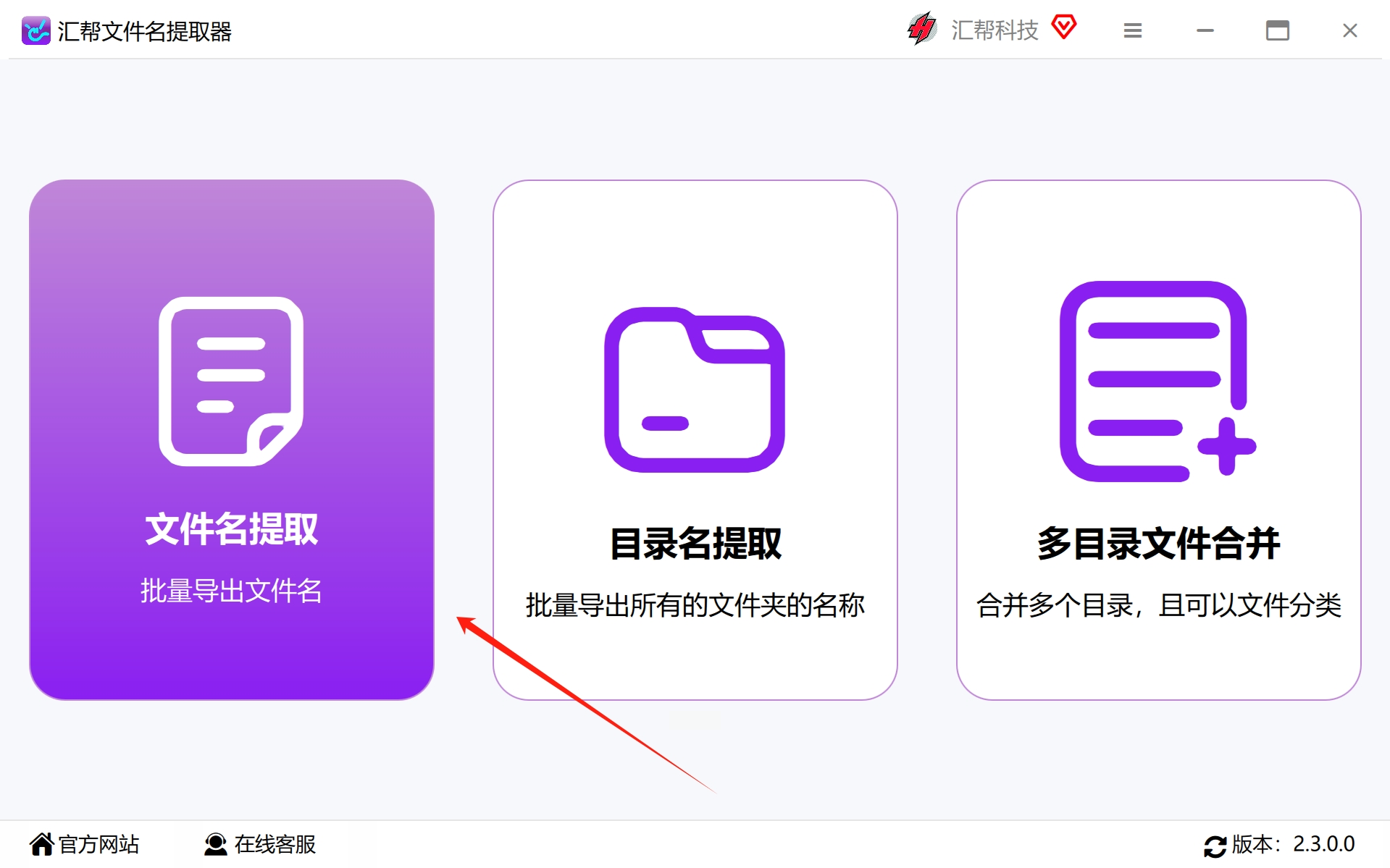
步骤3,通过点击“添加文件”或“添加目录”按钮,选中待提取目录下所有需要进行文件名提取的PDF文件,由此实现批量处理,并且无文件数量限制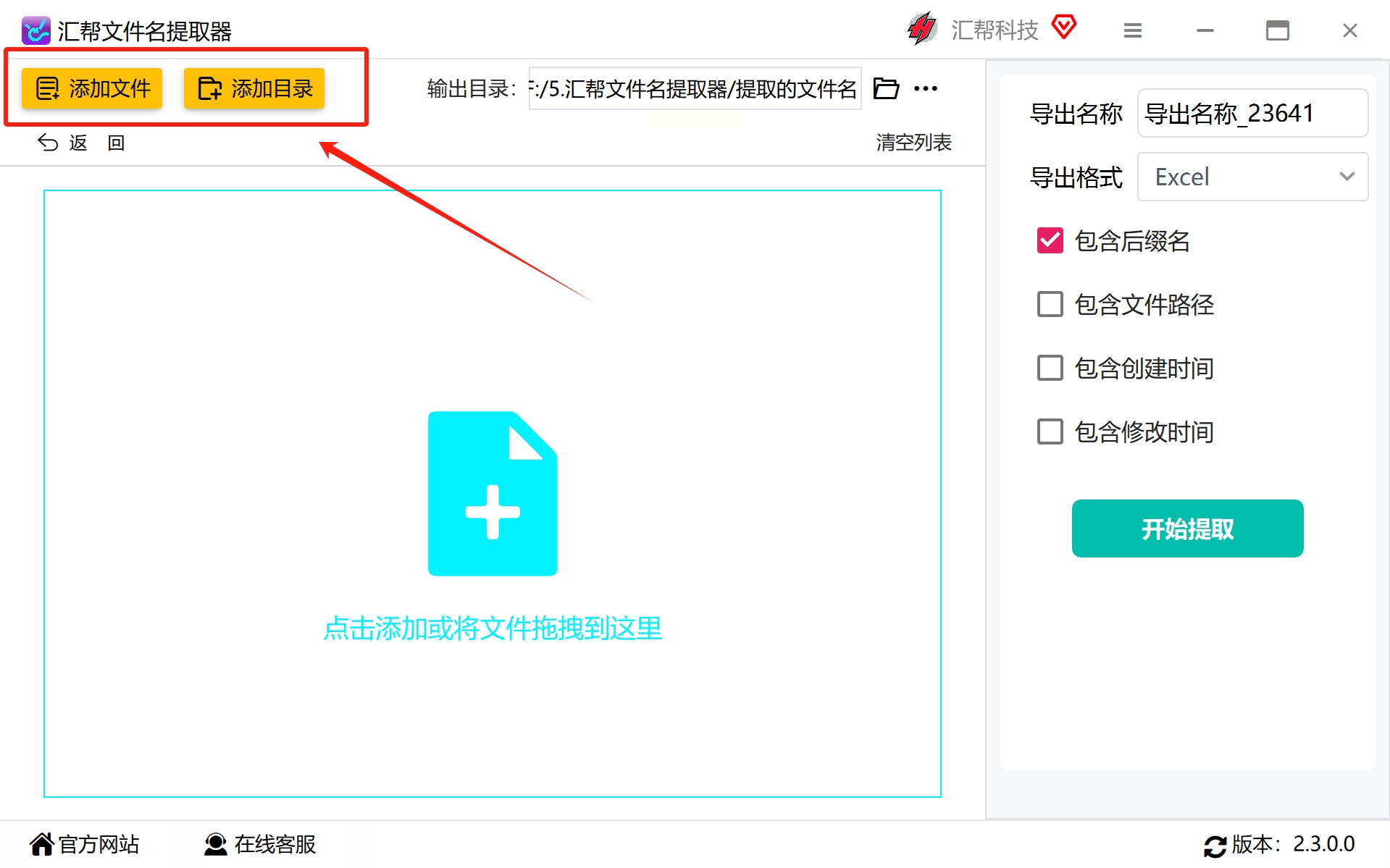
步骤4,设置相应的导出名称,如未作设定则将采用默认方式自动生成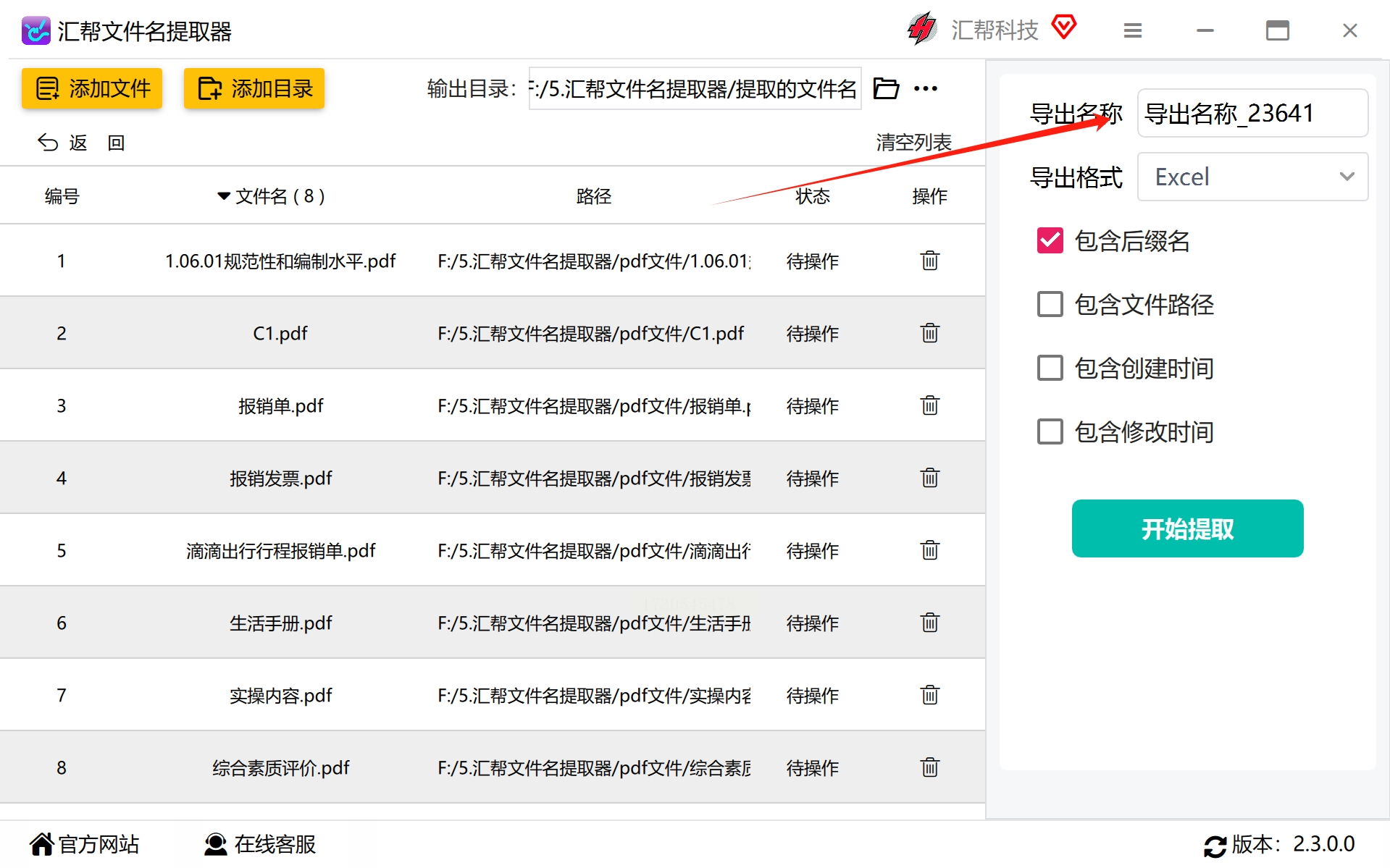
步骤5,根据实际需求选取欲导出的文件格式,可将文件名导入至以上所提到的三种文件类型中的任意一种,这里小编选择了excel文件格式。
步骤6,在下方进行选择,确定需要同时提取的元素内容,随后点击“开始提取”按键便可启动提取过程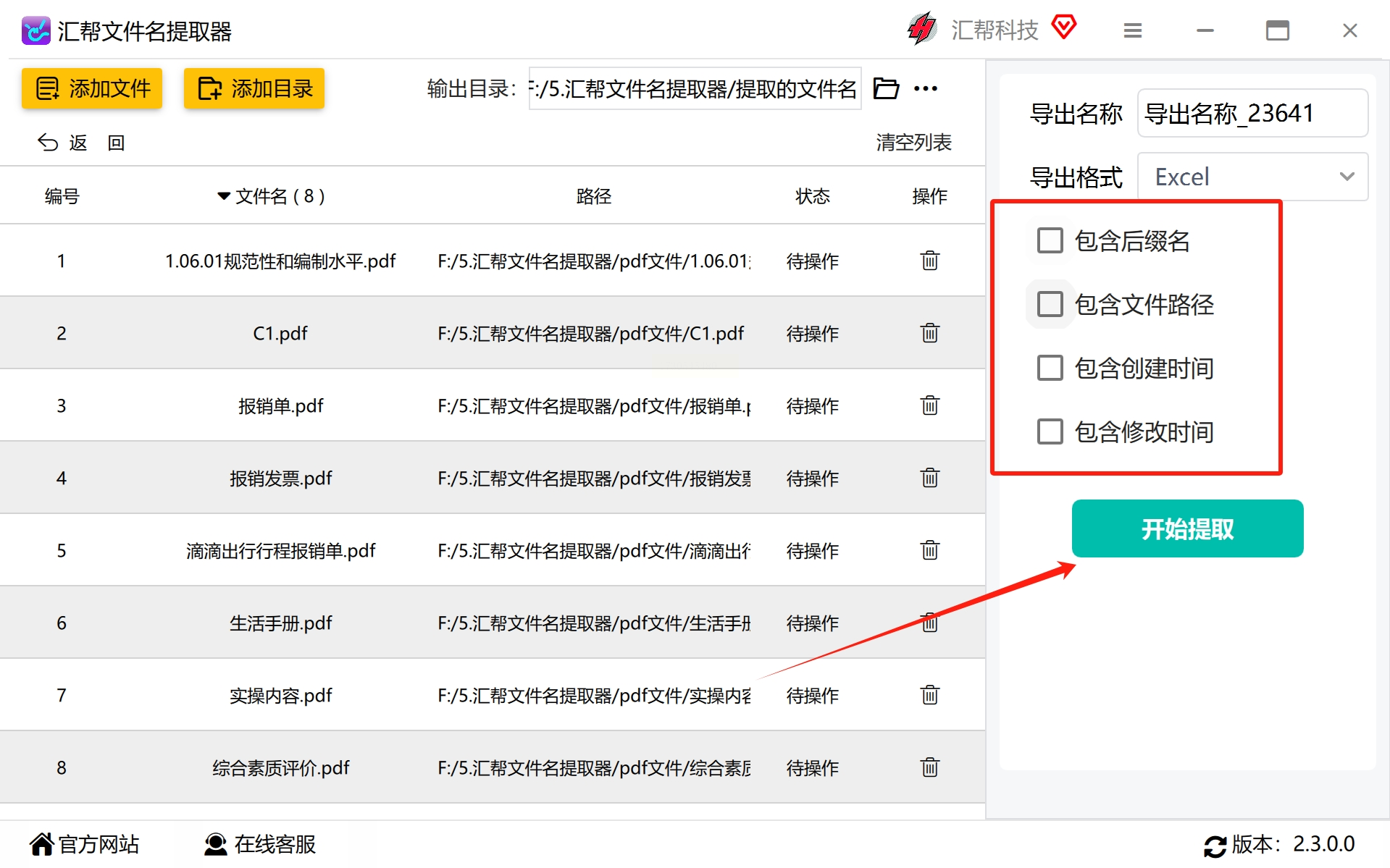
打开预设的文件后,您将发现PDF文件名均已成功提取其中,同时您还能轻松将这些文件复制下来运用到其他场合。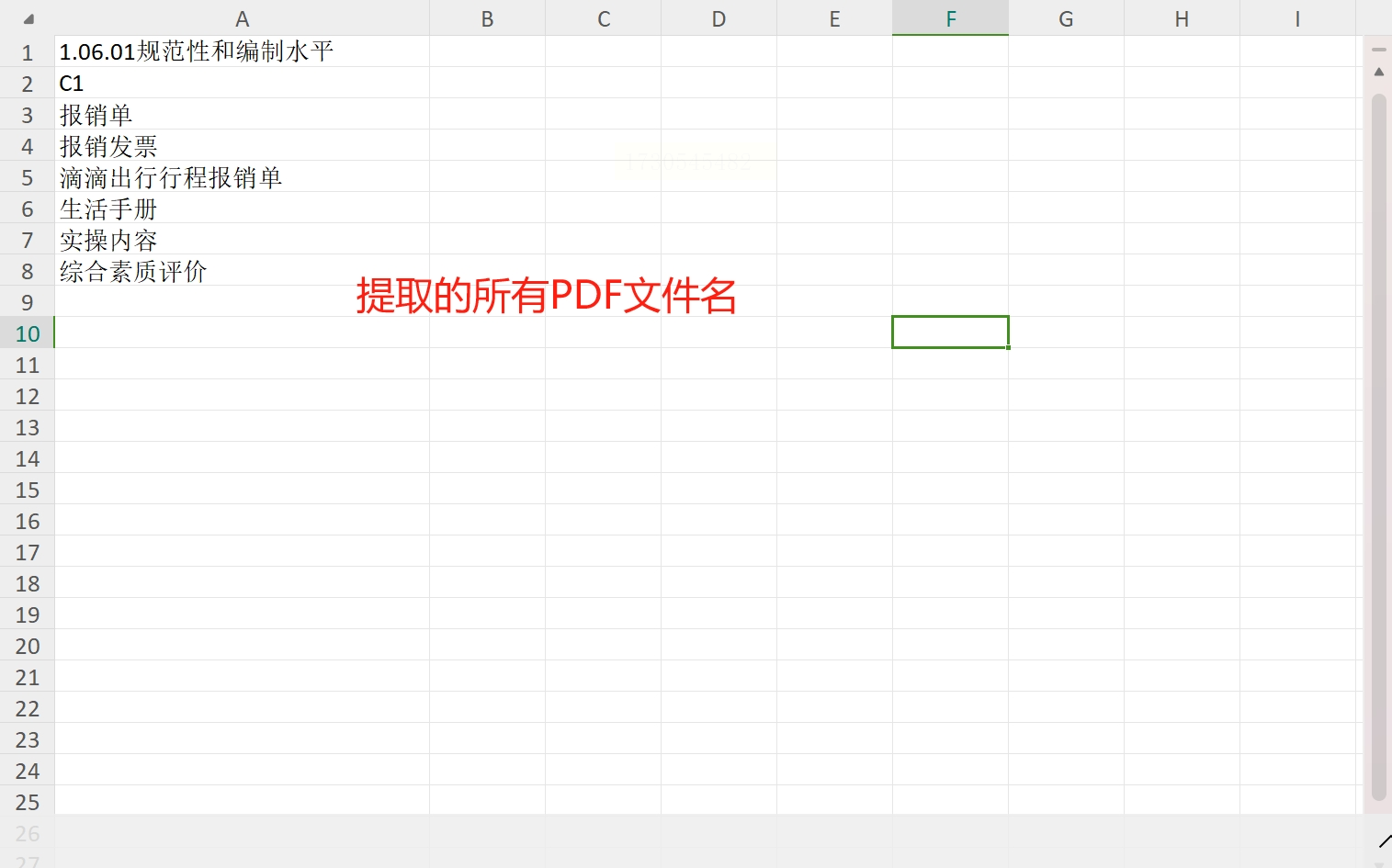
第2种方法:批量提取文件使用cmd命令提示符
PDF文件名批量复制到Excel之旅
在这个指南中,我们将指导您一步步地使用命令行来实现PDF文件名的批量复制到Excel。这种方法不仅可以提高您的工作效率,还可以帮助您更好地组织和管理您的电子文档。
第一步:打开命令提示符界面
首先,按下 Windows + R 键组合,在弹出的“运行”对话框中输入 `cmd` 并点击确定按钮。这样就可以打开命令提示符界面了。命令提示符界面类似于操作系统提供的控制台环境。
第二步:导航到PDF文件所在的目录
接下来,使用 `cd` 命令来改变当前目录。例如,如果您的 PDF 文件位于 C:\路径\到\你的\文件夹 中,请运行以下命令:
```cmd
cd /d C:\路径\到\你的\文件夹
```
这将把您移动到包含PDF文件的文件夹内。
第三步:生成PDF文件名列表
接下来,我们需要使用 `dir` 命令来列出所有 PDF 文件,并将它们保存到一个文本文件中。以下命令用于生成PDF文件名列表:
```cmd
dir /b *.pdf > filenames.txt
```
这会创建一个名为 `filenames.txt` 的文本文件,里面包含了所有PDF文件的名称。
第四步:导入文本文件到Excel
打开 Excel 并新建工作簿。选择“数据”选项卡,然后点击“从文本/CSV”,选择刚才生成的 `filenames.txt` 文本文件,并确保分隔符设置为“无”或“制表符”。最后,点击“导入”,并按照提示完成导入过程。
这样,您就成功地将PDF文件名批量复制到了Excel工作表中了!
附注:
1. 请注意,使用 `dir` 命令时,请确保在命令提示符界面中输入正确的路径和文件名前后添加 `/b` 或 `*.*` 等相关参数,以避免生成未经指定的文件名。
2. 如果您需要导入多个文本文件,请分别导入每个文件,然后合并为一个工作表。
希望本指南能够帮助您快速实现PDF文件名批量复制到Excel的需求!
第3种方法:使用Windows PowerShell命令
Windows PowerShell:一道解锁批量PDF提取之门
在 Windows 系统中,有一个强大的命令行工具,名为 Windows PowerShell。借助它,我们可以轻松地实现对 PDF 文件的批量操作,例如批量提取 PDF 文件名。让我们一步一步地了解如何利用 PowerShell 来解决这个问题。
第一步:熟悉 PowerShell 环境
PowerShell 是 Windows 系统内置的一个命令行工具,你也可以使用它来批量提取 PDF 文件名。要开始你的操作,首先需要了解 PowerShell 的基本环境。通过在 PowerShell 提示符中输入 `Get-ChildItem` 命令,可以看到该工具的强大功能。
第二步:筛选 PDF 文件
在 PowerShell 环境中,要实现批量提取 PDF 文件名,我们首先需要筛选出所有 PDF 文件。这个时候, `-Filter` 参数就派上用场了。通过使用 `Get-ChildItem` 命令加上 `-Filter *.pdf` 的参数,可以只获取当前目录下所有的 PDF 文件。
第三步:获取 PDF 文件名
筛选完成后,我们需要从这些 PDF 文件中提取它们的文件名。这时候, `Select-Object -ExpandProperty Name` 参数就可以实现了。通过在 `-Filter *.pdf` 的基础上添加这个参数,可以直接将每个 PDF 文件的名称输出到 PowerShell 中。
第四步:批量提取 PDF 文件名
现在,我们已经掌握了筛选和获取 PDF 文件名的方法。最后一步就是要将这些信息整理出来,形成一个可视化的PDF文件列表。这时候,你就可以通过 `foreach`循环来遍历每个PDF文件名称,并分别打印出来。
第五步:保存 PDF 文件名
如果你想要将提取到的所有 PDF 文件名保存到一个文本文件中,那么这时候,就需要利用 Out-File 命令。Out-File 命令可以将 PowerShell 中的输出直接写入到一个指定的文件中,形成一个记录性质很强的PDF文件列表。
小提示
请注意,在使用这些 PowerShell 命令时,你需要确保当前用户有足够的权限来访问所要批量操作的 PDF 文件夹。否则,就会因为权限问题而无******常执行命令。在某些情况下,你可能需要以管理员身份运行 PowerShell 才能顺利完成任务。
总之,通过这五步操作,我们就可以实现对 PDF 文件名的批量提取,并将它们保存到一个文本文件中。让我们进一步探索 PowerShell 的强大功能,以便更好地利用它们来解决我们的工作和生活中的各种问题!
第4种方法:批量使用"Small Boat File Name Handler"提取文件
一步步成为提取文件名高手
你是否有过这样的经历:面临数百甚至数千个PDF文件,需要从中提取文件名称,但又不知道如何开始?别担心,这里有一套简单易懂的步骤,将帮助你成为提取文件名高手。
第一步:准备好你的工具
首先,要有一个能干好这件事的工具。推荐使用的小船文件名批量处理器,一个专业的PDF文件管理软件。启动软件并选择“提取文件名称”功能。
第二步:添加目标PDF文件
接下来,将需要提取文件名的PDF文件添加到软件中。点击“添加文件”按钮,或是直接拖拽文件到软件界面上。确保所有需要提取文件名的PDF文件都已成功添加。
第三步:设置提取条件
在文件添加完成后,软件右侧会显示“提取内容”设置区域。在这里,你可以根据自己的需求进行设置。但是,通常只需要默认设置即可,因为我们的目标是提取文件名。
第四步:定制导出选项
接下来,要确定如何保存提取结果。设置导出的名称和格式,在软件的相应位置输入你希望导出的Excel文件的名称,并选择“xlsx”作为导出格式。这是Excel表格的标准格式,非常方便。
第五步:开始提取文件名
确认所有设置无误后,就可以点击软件界面上的“开始提取”按钮了。软件将开始批量提取PDF文件的文件名,并将提取结果保存到之前设置的Excel文件中。这一步骤可能需要一些时间,取决于文件数量。
第六步:查看提取结果
提取完成后,软件通常会提示你提取成功,并提供前往导出文件夹的快捷方式。点击“前往导出文件夹”,打开保存提取结果的Excel文件所在的位置。在Excel文件中,你将看到所有被提取的PDF文件名已经整齐地排列在表格中。
通过遵循这些步骤,你就可以轻松地批量提取PDF文件的名称,将你的工作效率大大提高。
第5种方法:批量提取PDF文件名:使用Python脚本的高效方法
在当今数字化时代,处理大量PDF文件是常见的问题。在此背景下,提取PDF文件的名称成为一种必要的技能,以便于更好地管理和维护这些文件。利用Python编程语言,可以轻松实现批量提取PDF文件名的功能。
步骤一:准备Python环境
首先,确保你的电脑上已经安装了Python环境。如果你还没有安装,建议前往官方网站下载最新版本,并按照指引进行安装。在安装完成后,记得将Python添加到系统的PATH变量中,以便于在命令行或IDLE中直接运行脚本。
软件名称:汇帮文件名提取器
下载地址:https://www.huibang168.com/download/wGi5oWZ2FL8S
步骤二:导入必要模块
接下来,我们需要导入Python中的os模块。os模块是与操作系统相关的一个模块,它提供了一个简单易用的接口,用于执行文件和目录管理等操作。在你的Python脚本中,添加以下代码来导入所需模块:
```python
import os
```
步骤三:定义PDF文件名提取函数
下一步是定义一个函数,该函数负责提取指定路径下的所有PDF文件的文件名。我们将这个函数命名为`get_pdf_file_names()`,如下所示:
```python
def get_pdf_file_names(path):
pdf_file_names = []
for root, dirs, files in os.walk(path):
for file in files:
if file.endswith(".pdf"):
pdf_file_names.append(os.path.join(root, file))
return pdf_file_names
```
在这个函数中,我们使用`os.walk()`方法遍历指定路径下的所有文件夹及其子文件夹。然后,对于每个文件,我们判断是否以`.pdf`为扩展名,如果是,则将其添加到`pdf_file_names`列表中。最后,返回该列表中的PDF文件名称。
步骤四:使用脚本
至此,我们已经定义了一个能够提取PDF文件名的函数。现在,我们可以在Python中直接运行这个脚本了。在脚本中,定义一个变量来保存需要遍历的路径,并将其传递给`get_pdf_file_names()`函数。
```python
path = "/path/to/your/pdf/folder"
pdf_files = get_pdf_file_names(path)
print(pdf_files)
```
这段代码将会输出该文件夹及其所有子文件夹中所有PDF文件的文件名。其中,'/path/to/your/pdf/folder'应该替换为实际包含PDF文件的路径。
总结
通过这些步骤,我们可以轻松地使用Python脚本批量提取PDF文件名。在实际应用场景中,这个功能将会显著提高你的工作效率和管理能力。
高效的PDF文件管理技巧
在日常工作或学业中,我们经常处理大量PDF文件,例如报告、合同、研究资料等。手动记录每个文件名称是耗时且容易出错的,这种方式简直是在浪费时间和精力。但现在我们有了更好的选择——快速批量提取PDF文件名。这个技能能够帮助你高效地管理文档库,节省大量时间成本。在专业人士看来,这个技巧是至关重要的,它能让他们更快捷地处理工作。
使用适合你的工具或编写简单的脚本程序都可以实现这一点。你只需轻松触发它,然后就可以获得所需文件名列表。这种效率提升对我们来说无疑是福音。这也是为什么说,高效的PDF文件管理技巧是一种至关重要的技能的原因。通过掌握这种技巧,我们不仅能节省大量时间,还能提高工作效率,让自己更轻松地应对工作挑战。
如果想要深入了解我们的产品,请到 汇帮科技官网 中了解更多产品信息!
没有找到您需要的答案?
不着急,我们有专业的在线客服为您解答!

请扫描客服二维码

