登录
- 微信登录
- 手机号登录
微信扫码关注“汇帮科技”快速登录
Loading...
点击刷新
请在微信【汇帮科技】内点击授权
300秒后二维码将过期
二维码已过期,点击刷新获取新二维码
登录
登录
其他登录方式
修改日期:2024-11-17 20:00
快速导出大量PDF文件名至Excel - 四大高效方法!通过批量提取PDF文件名的操作,不仅能够显著提升数据检索的速度与准确性,更能在无形中解放人力,让使用者将精力聚焦于更具价值的工作任务上。这一技术的应用不仅可以优化个人的工作流程,同时在组织层面也能够大幅提升工作效率和资源利用效率。
批量提取PDF文件名不仅是一项实用的技术手段,更是推动信息时代高效运作不可或缺的一环。通过优化这一过程,不仅能提升个人的工作效率,更能够为组织带来创新与竞争力的双重提升。

如何使用“汇帮文件名提取器”批量处理PDF文件名
---
一、启动安装
初次接触“汇帮文件名提取器”的用户,请首先在互联网上搜索并找到此软件的官方网站或安全可靠的下载链接,完成对软件的下载。确保你将下载至个人计算机中进行安装。
软件名称:汇帮文件名提取器
下载地址:https://www.huibang168.com/download/wGi5oWZ2FL8S
---
二、点击功能与导入文件
成功安装后启动软件,选择“文件名提取”这一核心功能选项。通过点击主界面上的“添加文件”或“添加目录”,轻松选中位于电脑硬盘内需要进行批量处理的PDF文件。无论单个文件还是整个文件夹中的所有文档,都可一网打尽。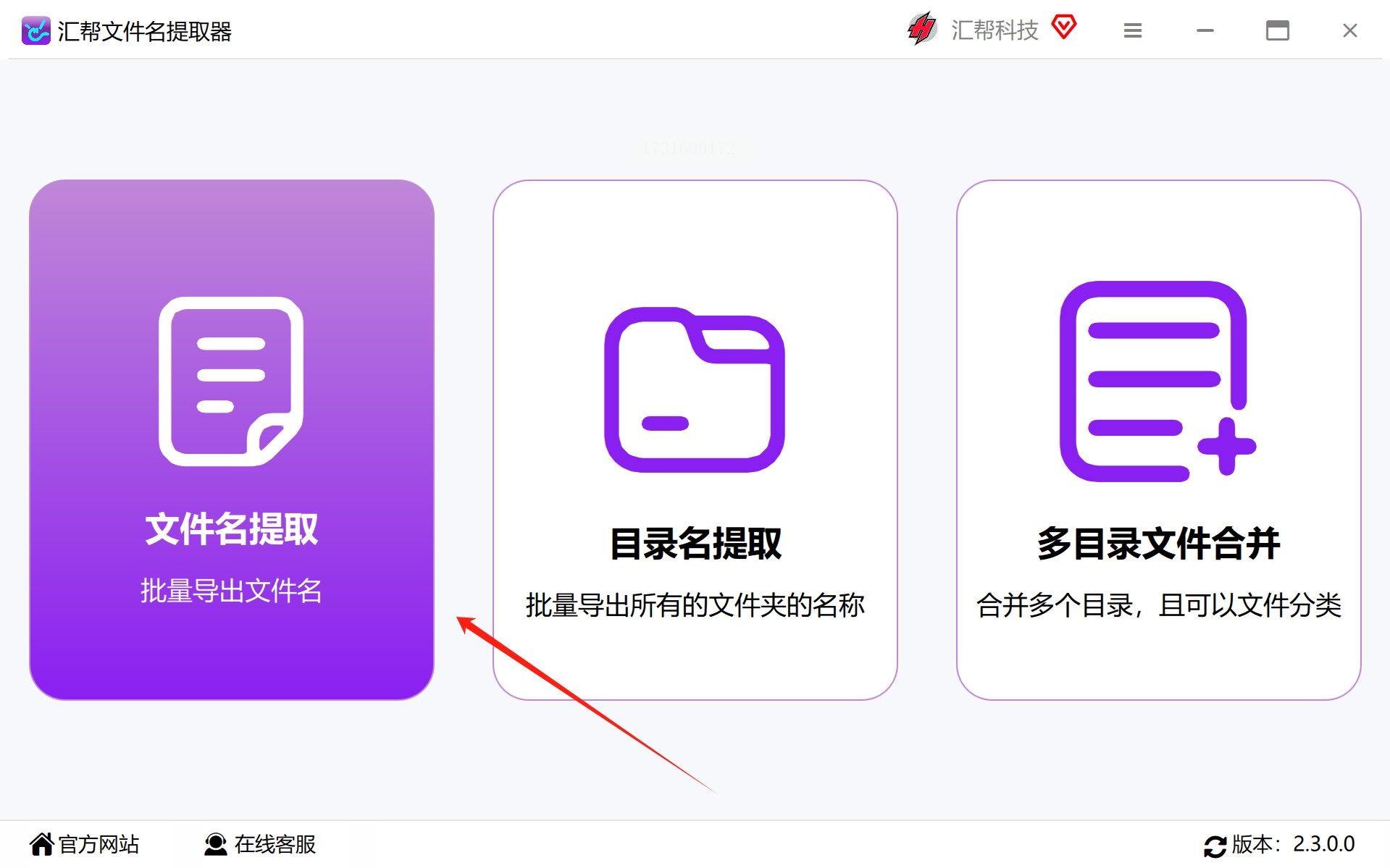
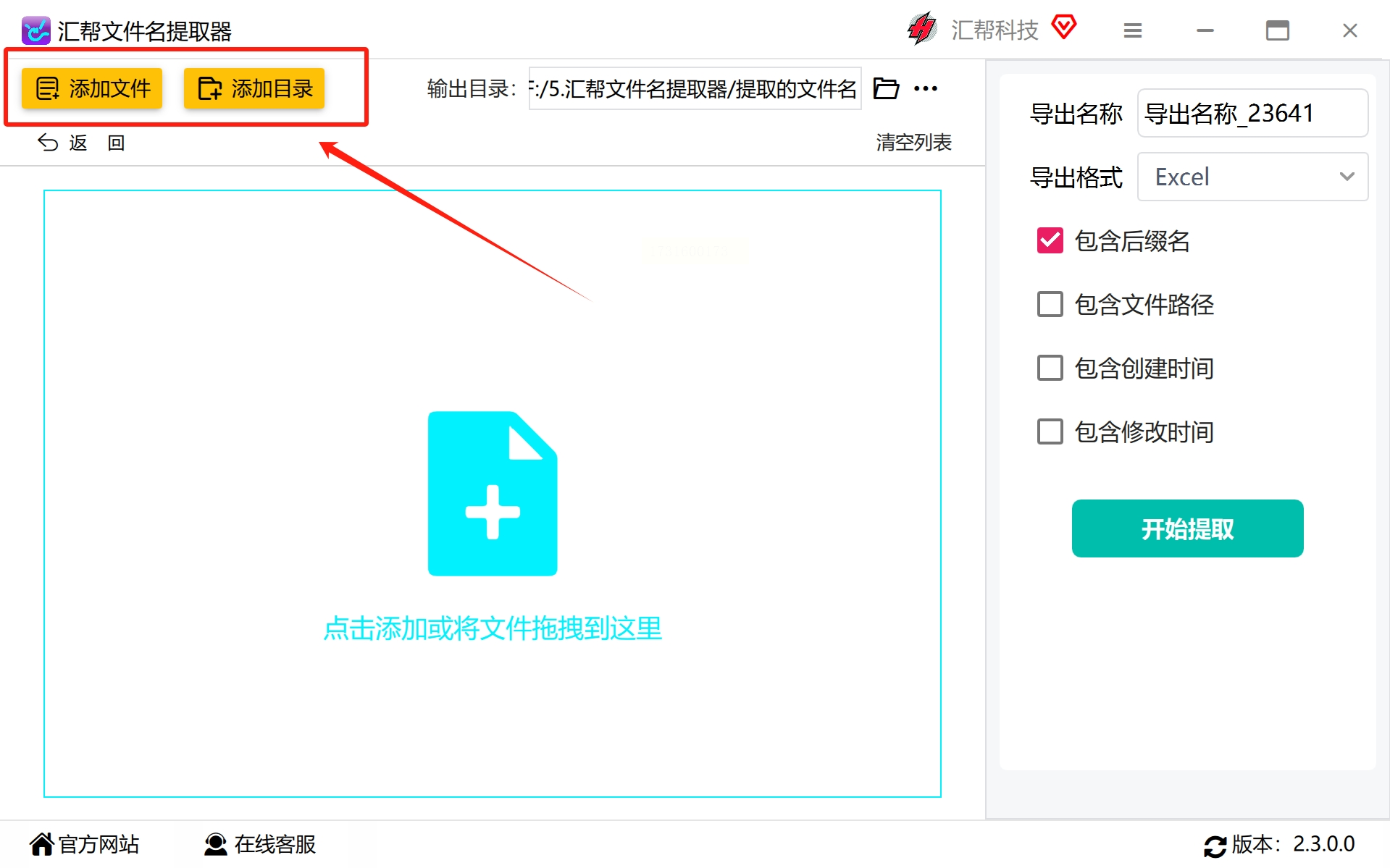
---
三、自定义输出
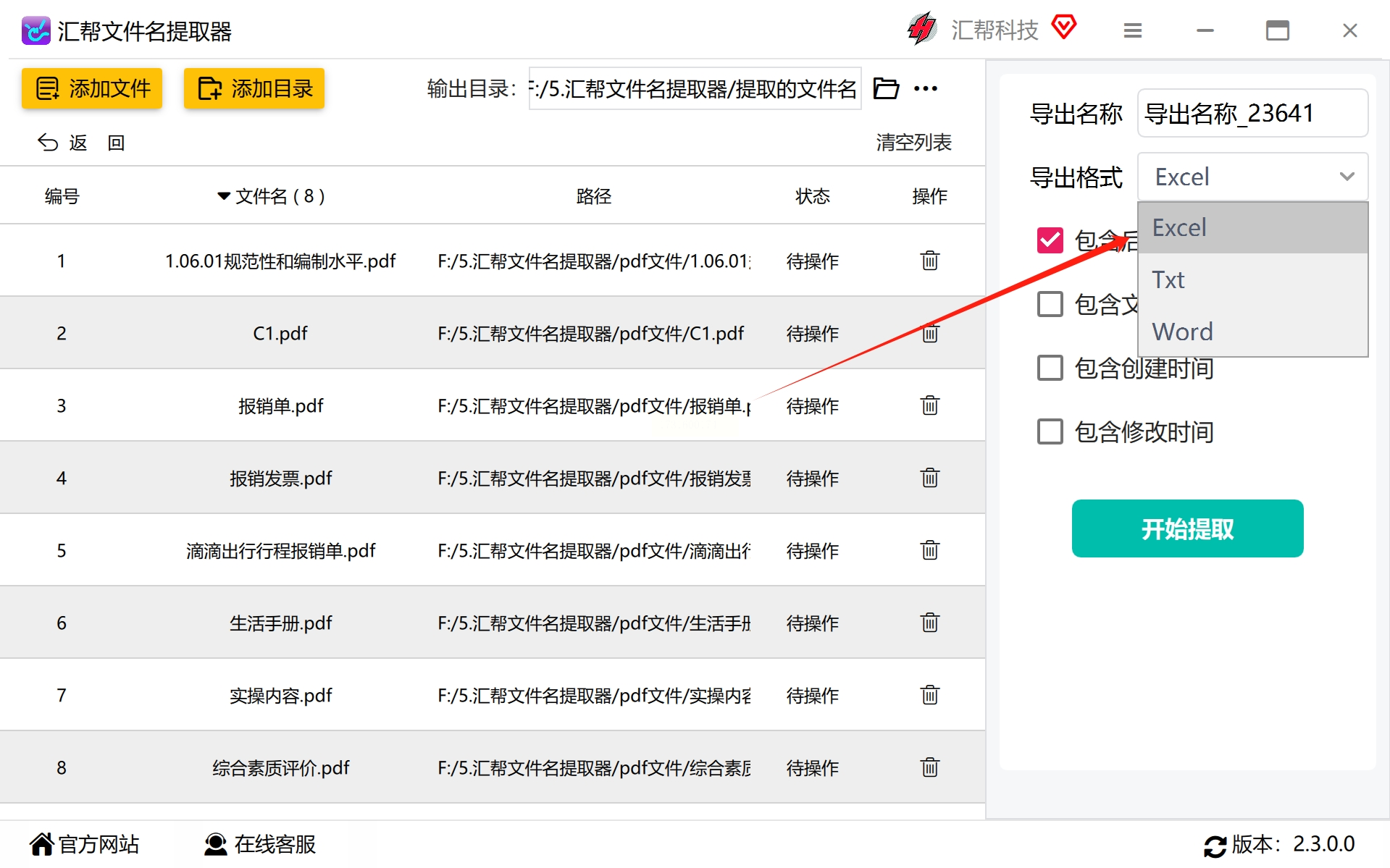
在软件界面中设置导出名称,如未设定,则会自动使用系统提供的默认命名规则生成新文件。进一步选择你偏好的导出格式:文本、CSV或Excel,以便于后续的数据整理和分析需求。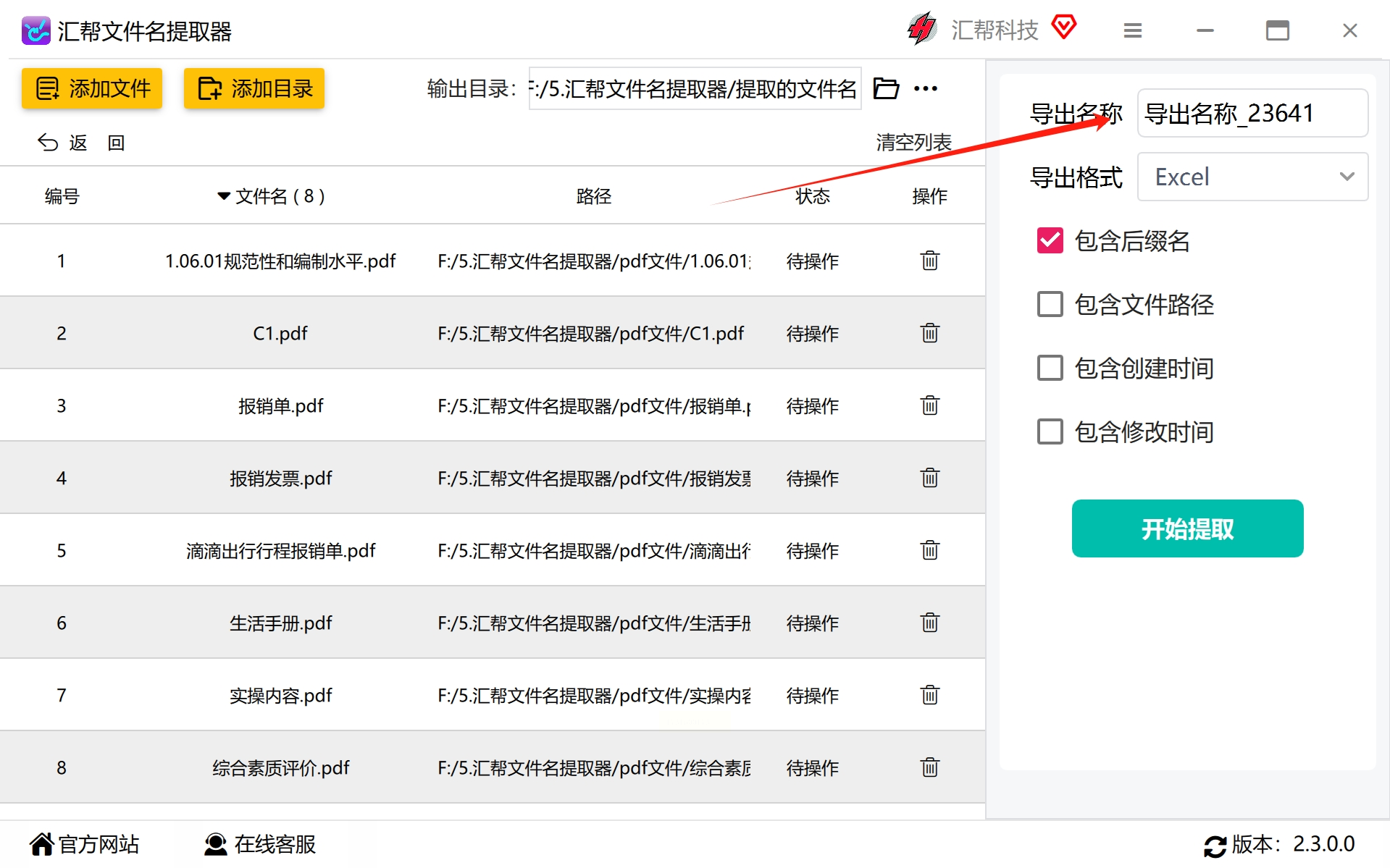
---
四、配置更多选项
根据具体需求调整后缀名、文件路径、创建时间、修改时间等细节设置,确保每一步操作都符合预期的标准化流程。确定好各项参数后,点击“开始提取”按钮,软件将自动处理所有指定文件,并按设定规则生成新的输出文档。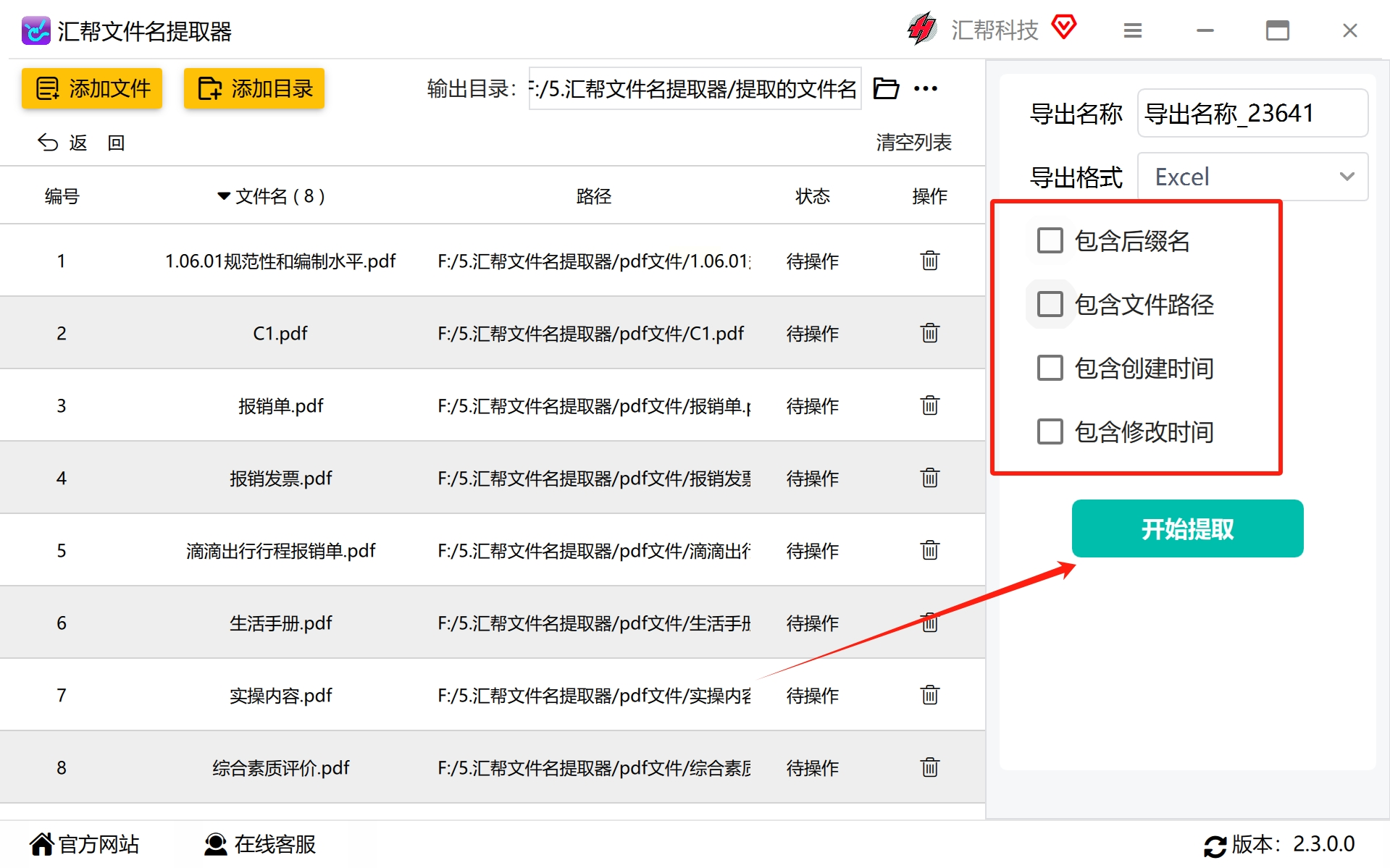
---
五、检查与导出
当提取过程完成后,系统会以弹窗形式告知任务已完成。这时,只需转至你预先设置的输出路径内,查找并下载生成的Excel或CSV格式文件即可。打开预设文件后,你会发现所有PDF文件名已成功被识别和分类。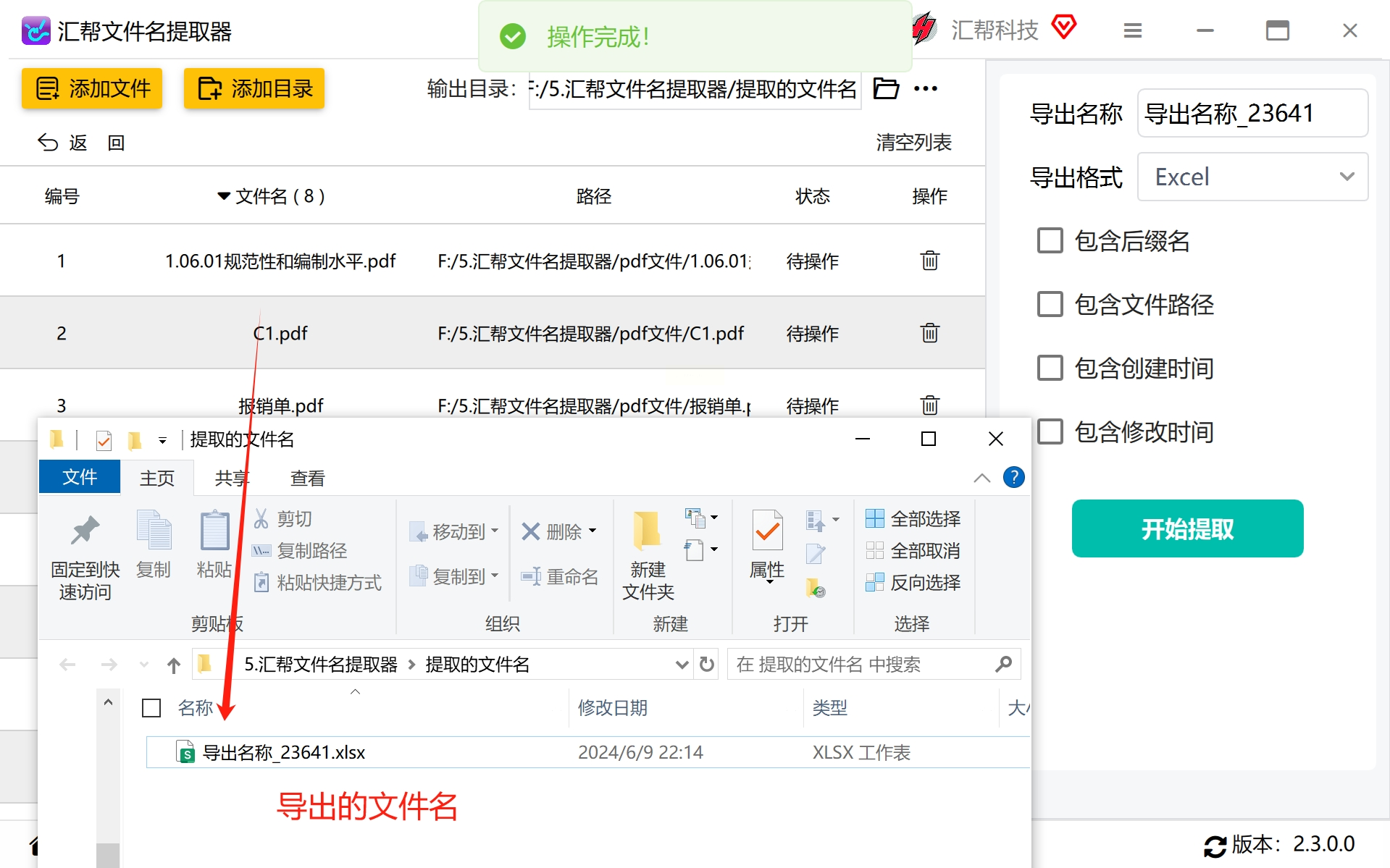
---
六、灵活运用
这些提取出的文件名不仅可作为数据导入至其他软件进行进一步分析的基础,还能够迅速复制到所需应用中,比如用于数据报告、文档归档或是项目管理等领域。高效地为日常工作或项目带来便利与效率提升。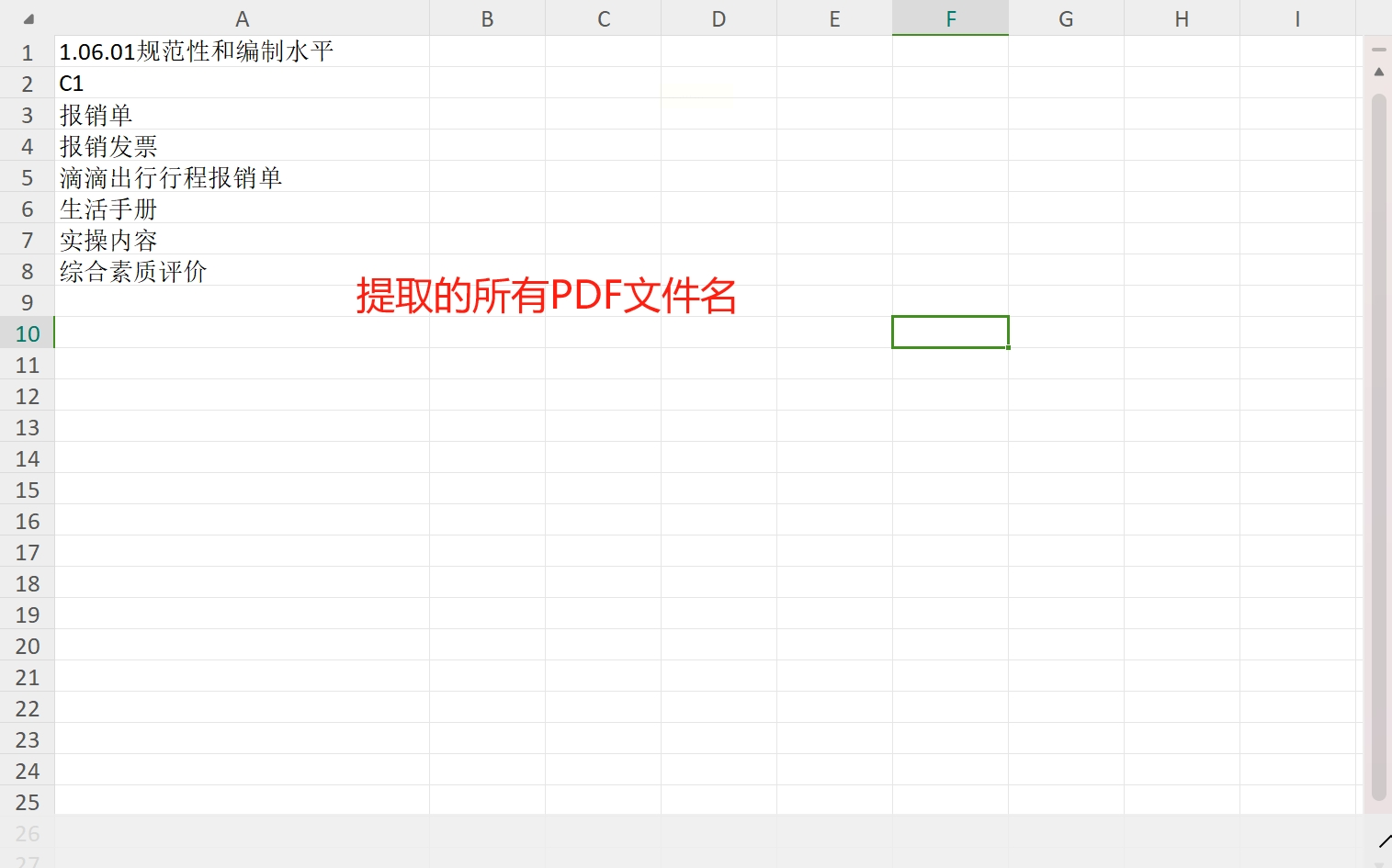
---
通过“汇帮文件名提取器”,用户不仅能快速批量处理大量PDF文件的名称信息,还能根据实际需求灵活配置输出格式和自定义设置。从安装到使用,每个步骤都旨在提高生产力与用户体验,使得数据管理流程更为简洁流畅。
在数据管理过程中,将文件列表转换为电子表格是一个常见的需求。本文将介绍如何使用命令提示符(CMD)和Microsoft Excel进行这一操作,使您能够便捷地从PDF文件夹中提取所有文件名称,并将其导入到一个易于浏览的Excel表单。
步骤一:激活命令行窗口
首先,在计算机上打开Windows搜索框并输入“cmd”以启动命令提示符。此操作只需一步动作即可完成您的任务准备阶段。
步骤二:定位目标文件夹
在命令提示符中,您需要切换到包含PDF文件的特定目录。通过使用`cd`命令搭配路径名,您可以迅速定位至所需文件夹,如:
```
cd C:\your\path\to\pdfs
```
步骤三:生成文件名列表
通过执行以下命令,您可以将当前目录下的所有.pdf文件名称存储到文本文件中:
```
dir /b *.pdf > filenames.txt
```
这一步操作不仅高效地提取了所需信息,还便于后续的导入流程。
步骤四:整合数据至Excel
1. 启动Excel:在桌面或者快捷方式中打开Microsoft Excel应用。
2. 导入文本文件:
- 转向“开始”选项卡,点击“获取数据”,选择“从文本/CSV”以引入外部数据源。
- 导航到并选择您的`filenames.txt`文件作为数据来源。
3. 配置导入参数:在出现的窗口中,确保勾选了正确的分隔符(通常为无或制表符),点击“加载”或“导入”。
通过上述步骤和小技巧,您可以高效、轻松地将PDF文件名从命令提示符迁移到Microsoft Excel中。这一过程不仅节省了手动输入的时间成本,还为后续的数据分析提供了便利条件。立即开始您的数据整理之旅吧!
标题:批量提取PDF文件名的PowerShell脚本教程
一、前言
在日常工作中,处理大量的文档时常会遇到批量操作的需求。无论是需要整理文件名以供后续使用,还是进行其他形式的数据整理与分析,通过编程实现自动化处理无疑是高效的方法之一。本文将介绍如何利用Windows PowerShell进行这一任务的完成,包括脚本编写步骤、执行过程以及常见问题解决。
二、准备工作
1. 确保环境配置
确保您已安装Windows PowerShell或PowerShell Core(PS Core)。如果未安装,请访问官方网站下载并安装。
软件名称:汇帮文件名提取器
下载地址:https://www.huibang168.com/download/wGi5oWZ2FL8S
2. 了解PowerShell基础操作
学习如何在命令提示符中启动PowerShell,以及基本的命令执行、变量赋值等基础知识。
三、脚本编写
1. 定义文件夹路径
```powershell
$pdfDirectory = "C:\Path\To\Your\PDF\Folder"
```
2. 筛选并获取PDF文件名
利用`Get-ChildItem`命令查找指定目录下的所有PDF文件,并通过管道('|')传递给`Select-Object`来提取所需的属性:
```powershell
$pdfFilenames = Get-ChildItem -Path $pdfDirectory -Filter "*.pdf" -File | Select-Object -ExpandProperty Name
```
3. 输出或保存文件名
通过`Write-Output`命令将PDF文件名逐个显示在控制台上,或使用`Out-File`命令将所有文件名保存到文本文件中:
```powershell
foreach ($filename in $pdfFilenames) {
Write-Output $filename
# 将输出结果保存至文件中,例如:C:\output\PDF_filenames.txt
Get-ChildItem -Path $pdfDirectory -Filter "*.pdf" -File | Select-Object -ExpandProperty Name | Out-File "C:\output\PDF_filenames.txt"
```
四、执行脚本与运行注意事项
1. 执行命令
在PowerShell中输入上述代码并按回车键执行。确保在执行时,所指定的文件夹路径不存在任何拼写错误或语法问题。
2. 权限与安全考虑
运行脚本可能需要管理员权限,特别是在访问受限或敏感文件夹时。检查脚本的运行环境是否允许进行此操作。
3. 处理特殊情况
考虑到PowerShell脚本执行过程中可能出现的问题(例如错误信息、路径问题等),请确保及时排查并修正脚本中的错误。
五、后续步骤与优化
1. 调整脚本逻辑以适应特定需求
根据您的具体任务,可能需要对脚本进行进一步的定制。比如处理PDF文件中包含特殊字符的名称、或者在不同的操作系统环境下的适配等。
2. 编写错误处理代码
通过添加`Try...Catch`语句块来捕获并处理执行过程中的异常情况,确保脚本的健壮性和用户体验。
3. 自动化与集成
结合任务调度程序(如Windows Task Scheduler)定期运行此脚本,或将其整合到更复杂的工作流程中,实现自动化处理和数据管理。
Python批量提取PDF文件名的精简教程
一、预备工作
在我们开始之前,请确保你的系统上已安装了Python环境以及相关的库。你将会需要使用`os`模块来与操作系统进行交互,`os.path`子模块用于处理路径相关操作,并可能用到`glob`模块(如果其功能能满足需求)。
二、定义目标文件夹
首先明确你的工作目录和目标PDF文件存放的目录。假设目标目录为 `/home/youruser/documents/pdf_files`。通过简单的Python脚本,你可以轻松地访问和处理任何位于该路径下的PDF文件:
```python
import os
target_dir = "/home/youruser/documents/pdf_files"
# 或使用 glob 模块更简洁的方式:
# target_pattern = f"{os.path.abspath(target_dir)}/*.pdf"
```
三、识别并提取PDF
下一步是识别目标目录中的所有`.pdf`文件。这里,我们将展示如何遍历目录结构,并收集所有的匹配文件名:

四、执行脚本
运行上面定义的函数或脚本,它将立即列出所有符合指定条件的PDF文件。这不仅节省了手动查找的时间,还提供了自动化处理的可能性。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
通过上述方法的选择与运用,我们可以高效、准确地从海量PDF文件中提取信息,无论是对于个人工作还是企业运营都具有重要的实用价值。本文总结了多种解决方案,旨在为用户提供更多元化的处理方式,从而提升PDF文档处理的效率与效果。
如果想要深入了解我们的产品,请到 汇帮科技官网 中了解更多产品信息!
没有找到您需要的答案?
不着急,我们有专业的在线客服为您解答!

请扫描客服二维码

